Redis学习笔记
学习地址:https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0
前言:网站的瓶颈
- mysql单表超过300w要建立索引,否则会感觉查询速度明显降低
- 访问量(读写混合),一个服务器承受不了
只有开始出现以上情况,就要考虑晋级,例如:
-
读写分离
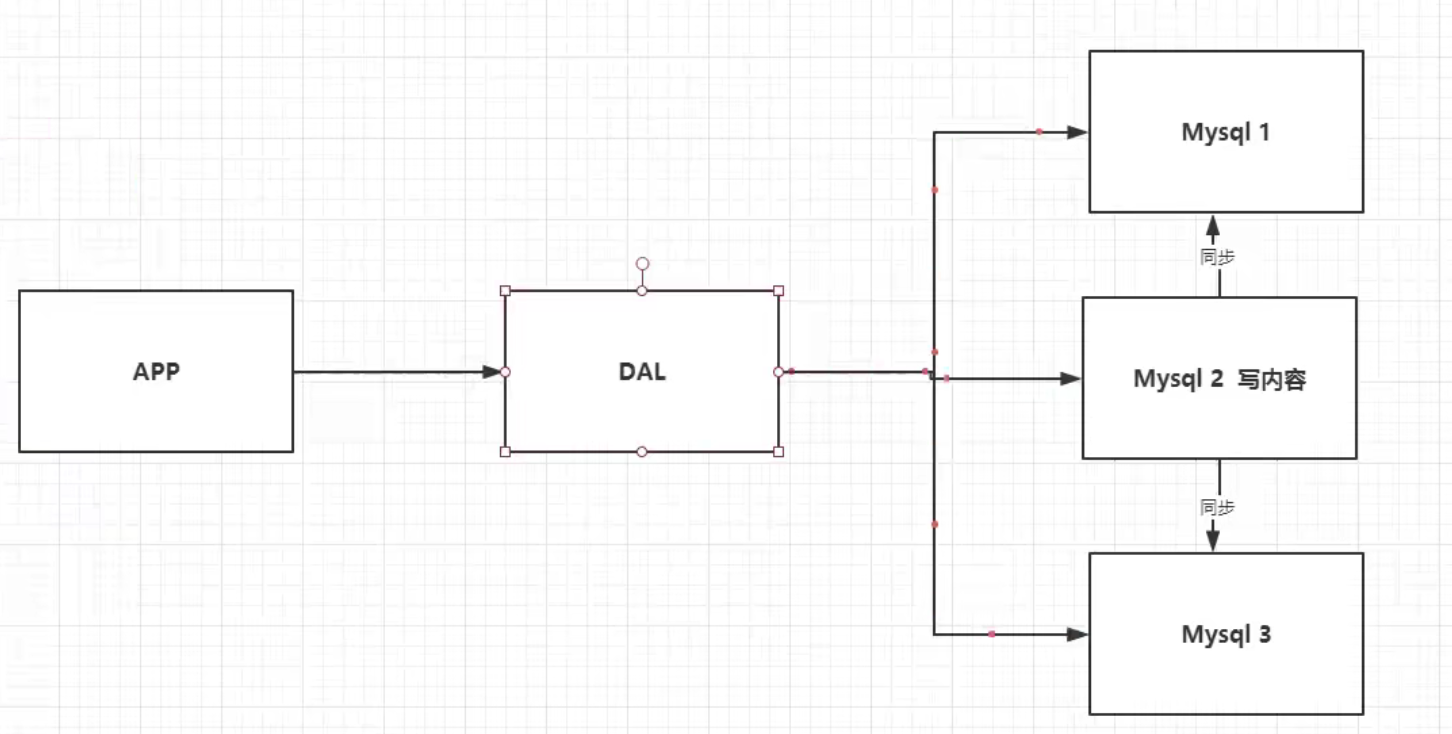
MyCat?
-
缓存,减轻数据库压力,对于相同的查询直接走缓存
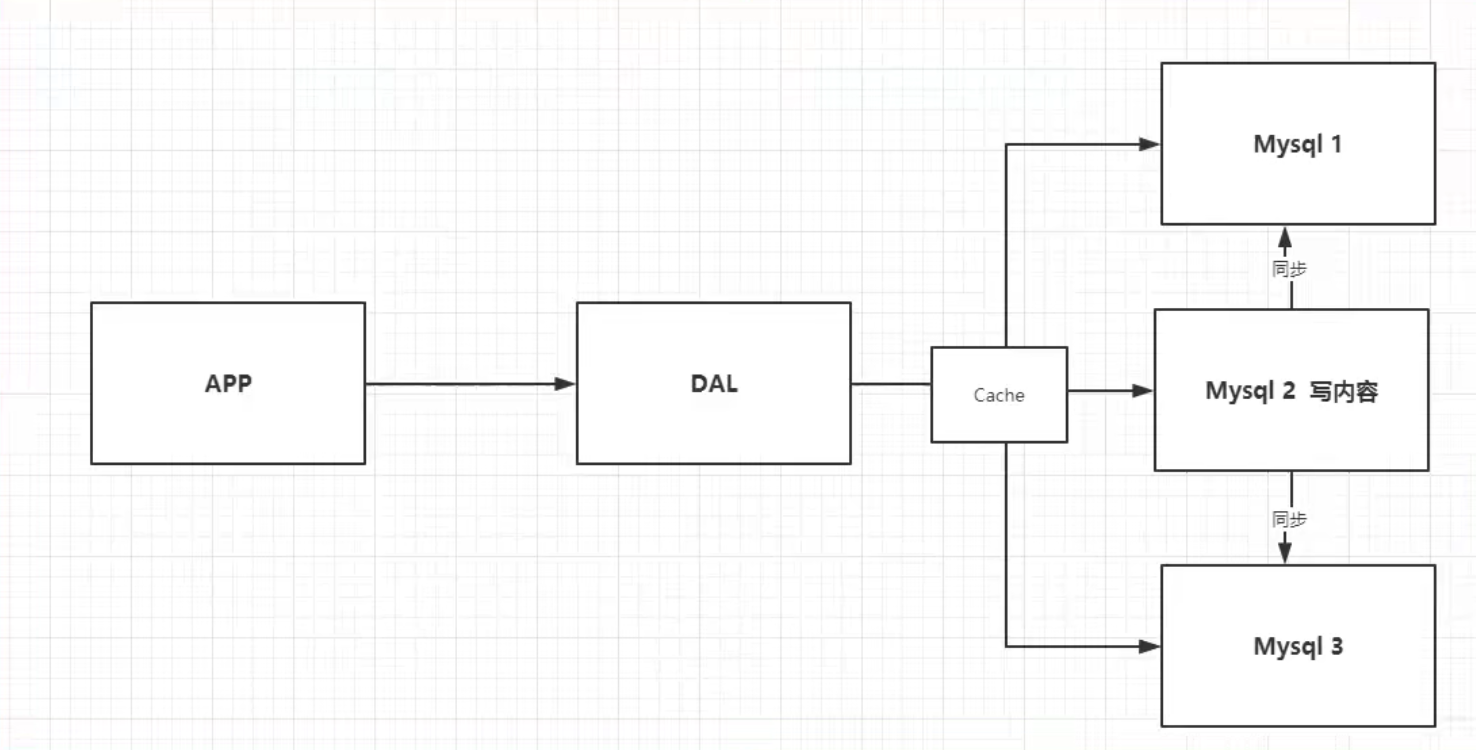
-
分库分表+mysql集群
一、Redis基本知识
1.切换数据库
- redis一共有16个数据库,默认使用第0个数据库
- 使用
select 3切换到第四个数据库 - 使用
dbsize查询数据库大小
2.常用指令
> keys * #查看所有key
> flushdb #清空当前库
> flushall #清空全部数据库
keys * #查看所有key
flushdb #清空当前库
flushall #清空全部数据库
exists [key] #查询某个key是否存在
expire [key] [秒] #设置某个key几秒后过期
ttl [key] #查看当前key的剩余时间 秒
type [key] #查看key的类型
3.单线程
要明白Redis是很快的,官方表示,Redis是基于内存操作,CPU不是 Redis性能瓶颈,Redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线程来实现,就使用单线程了!同时单线程还可以避免很多问题。
Redis为什么单线程还快?
- 误区1:高性能服务器一定是多线程的
- 误区2:多线程(CPU上下文切换)一定比多线程效率高
- 核心:redis是将所有的数据全部放在内存中的,所以说使用单线程云去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!!!),对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳的方案!核心:redis是将所有的数据全部放在内存中的,所以说使用单线程云去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!!!),对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,在内存情况下,这个就是最佳的方案!
4.作用
-
可以当作数据库、缓存、消息中间件MQ(发布订阅)
-
Redis是一个开源(BSD许可)的,内存中的数据结构存储系统,它可可以用作数据库、缓存和消息中间件MQ。它支持多种类型的数据结构,如字符串(strings),散列(hashes),列表(lists) 集合(sets),有序集合(sorted sets)与范围查询 bitmaps,hyperloglogs和地理空间(geospatial)索引半径查询。
Redis内置了复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRUeviction),事务(transactions) 和不同级别的磁盘持久化(persistence),并通过Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availabiility)。
知识点:
- 数据类型
- 复制
- LUA脚本
- LRU驱动事件
- 事务
- 哨兵
二、数据类型-对应的使用场景
1. 常见5种数据类型
- string
- list
- hash
- set
- sortedSet
2. 所有数据类型(九大)
前五种为常用,后三种为特殊,具体相关命令操作见 命令章节
| 数据类型 | 使用场景 | 备注 |
|---|---|---|
| String | 计数器:点赞数;微信文章阅读数(redis提供命令可以直接+1 -1);商品编号、订单号生成(INCR key) | |
| list | 相当于一个链表,可以选择在链表左侧或右侧插入数据,中间也行,但效率偏低。可以当成一个消息队列(从左边进去LPUSH,从右边出来RPOP)。可以当成一个栈(左进左出) | value为list,相当于一个有序链表 |
| hash | 简单购物车(记录key用户:(value 商品id:商品总数)) | 对应 java中的 Map<String, Map<Object, Object>> |
| set | ①抽奖(例如:随机抽取2个二等奖,并自动在set中剔除抽过奖的(也可不删除)) —> redis自带命令,一条指令即可 ; ② 朋友圈点赞(点一下加到set,再点一下从set删除),可全部罗列(指令:SMEMBERS); ③微博共同关注(取交集,指令:SINTER)④qq可能认识的人(**取差集**,相关指令:SDIFF)5⃣️提供随机弹出(移除)功能,可用于抽奖 6⃣️取并集,求出共同好友 | 无序不重复,存入结构类似hash,key是string,value是一个set |
| sortedSet(zset)有序集合 | ① 根据商品销售对商品进行排序显示(指令 ZRANGE)②抖音热搜(指令 ZINCRBY) | |
| bigmaps 位图 | 略 | |
| hyperloglogs | 略 | |
| geospatial (地理位置) | 略 | |
| streams | 略 |
三、Redis事务
1.介绍
----- 队列 set set 执行 -----
流程:
1 开启事务 > multi
2 命令入队 > set k1 v1
> set k2 v2
3 执行事务 > exec 或 (取消事务 DISCARD)
-
一个事务中所有命令都会被序列化,在事务执行过程中,会按照顺序执行
-
不保证原子性:
-
编译型异常(队列中包含 语法命令错误):事务中所有命令都不会被执行
127.0.0.1:6379> multi OK 127.0.01:6379> set k1 v1 QUEUED 127.0.01:6379> set k2v2 QUEUED 127.0.01:6379> set k3v3 QUEUED 127.0.01:6379> getset k3 # 错误的命令 (error) ERR wrong number of arguments for 'getset'command127.0.01:6379>set k4v4 QUEUED 127.0.01:6379> set k5 v5 QUEUED 127.0.0.1:6379>exec#执行事务报错! (error)EXECABORT Transaction discarded because of previous errors.127.001:6379>getk5#所有的命令都不会被执行!(ni1) -
运行时异常:若事务中某个出错,其他命令是可以正常执行的,针对错误的命令会抛出异常
127.0.0.1:6379> set k1"v1" OK 127.0.0.1:6379>multi OK 127.0.01:6379> incrk1#会 执行的时候失败! QUEUED 因为字符串不能加减 127.0.0.1:6379>set k2 v2 QUEUED 127.0.01:6379> set k3 v3 QUEUED 127.0.0.1:6379> get k3 QUEUED 127.0.0.1:6379> exec 1rror) ERR value is not an integer or out of range #虽然第一条命令报错了,但是依旧正常执行成功了!23K4)"v3" 127.0.0.1:6379> get k2"v2" 127.0.0.1:6379> get k3"v3"
-
- 无隔离级别:所有命令在事务中并没有直接被执行,只有发起命令的时候才会执行,所以没有隔离级别的概念
2.命令
-
msetnx
msetnx k1 v1 k2 v2 # msetnx是原子性的,要么一起成功,要么一起失败
四、redis实现分布式锁
使用场景:多个服务间 + 保证同一时刻内 + 同一用户只能有一个请求(放置关键业务出现数据冲突和并发错误)
1.锁的分类
-
JVM层面的锁:单机版的锁 synchronzed、ReentrantLock
synchronzed 和 ReentrantLock区别:
- synchronzed:某个线程获得锁之后,其他线程会一直等待直到释放锁,容易造成线程积压
- ReentrantLock:使用 tryLock,超过一定时间放弃等待(超时时间,防止死等)
-
分布式微服务架构,拆分后各个微服务之间为了避免冲突和数据故障加入的一种锁,分布式锁
2.分布式锁实现方案
-
mysql
-
zookeeper
-
redis –> redisson lock\unlock
redis单线程,谁先来谁先获得锁
3.问题
-
redis除了用来做缓存,还有什么用法?
见2. 所有数据类型的使用场景
-
redis做分布式锁需要注意的问题?
-
redis是单点部署的,会有什么问题?
-
集群模式下,主从模式有没有什么问题?
-
redlock、redisson
-
redis分布式锁如何续期?看门狗?
4.应用
-
电商超卖【等待集成到hod项目进行练习,含完整解决方案】
涉及多个 后端服务,分布式架构部署,需要使用分布式锁,单机锁无效(因为获取的锁不是同一个锁)
图中server1111和server2222功能相同,只是集群部署
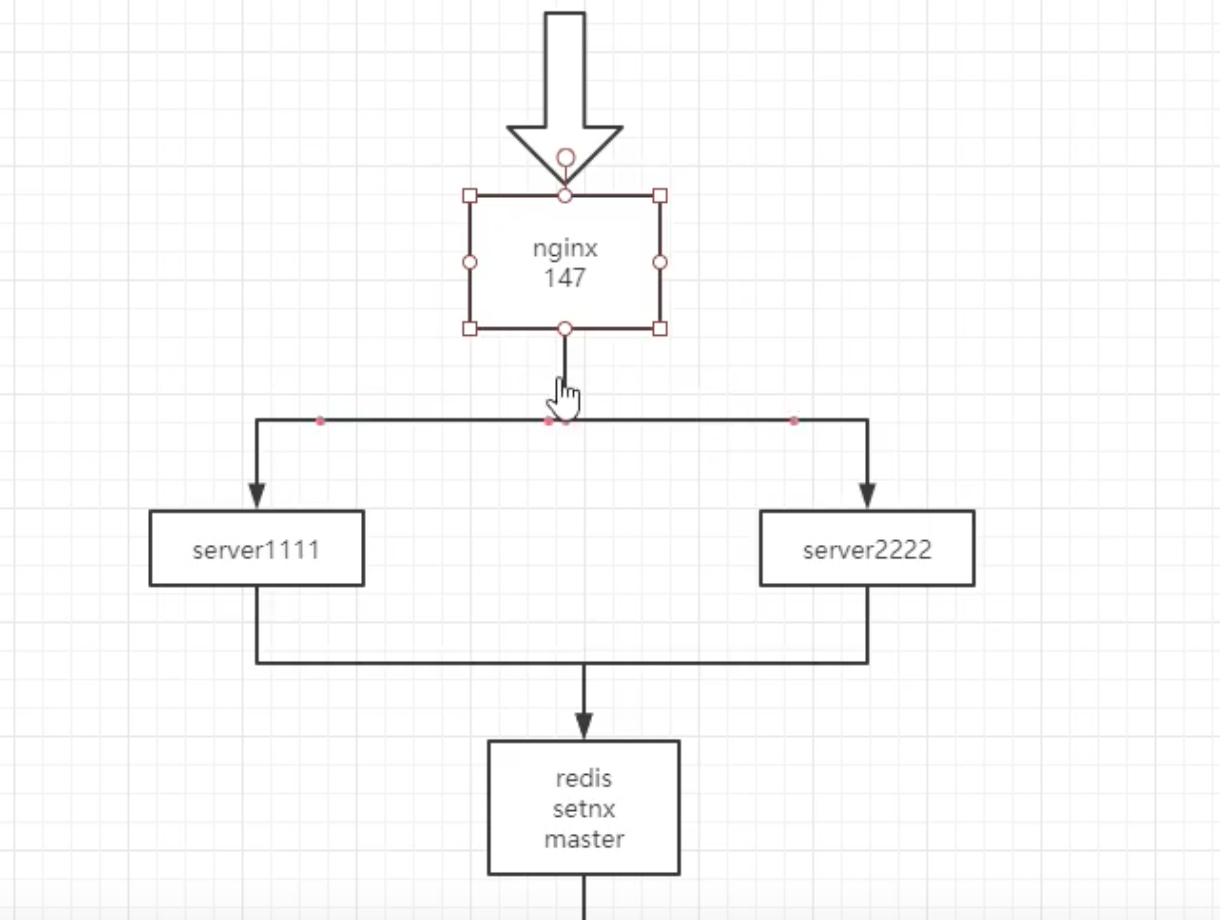
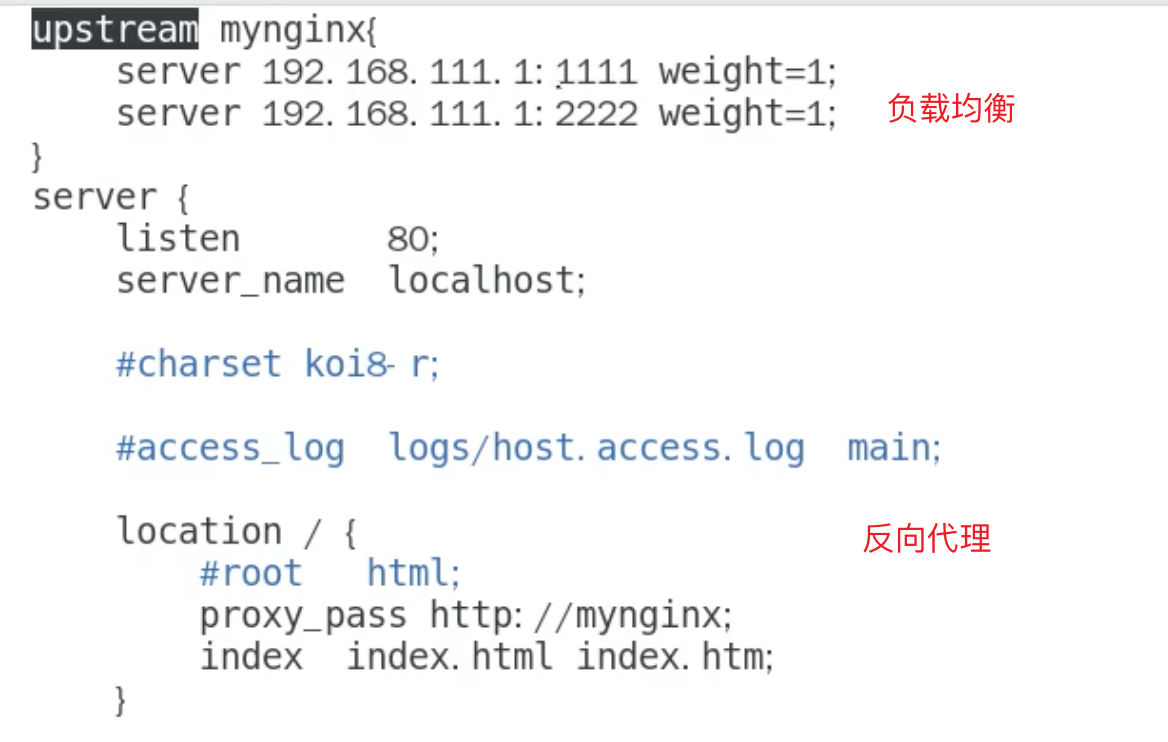
1:1的权重负载均衡访问到2台服务器上,使用Jmeter压力测试,可模拟多线程访问
思路以及问题解决思路:
-
商品数量存在redis中,每次售出扣减库存更新redis,直到卖完
-
采用2个服务一起售卖,考虑是否会超卖的问题
-
考虑程序不管正常执行还是异常执行都要能完成锁的释放(try finally)
-
考虑程序宕机无法解锁的情况 (加入过期时间 )

-
上面加锁和过期时间不具备原子性,需要同时加锁和过期时间设置
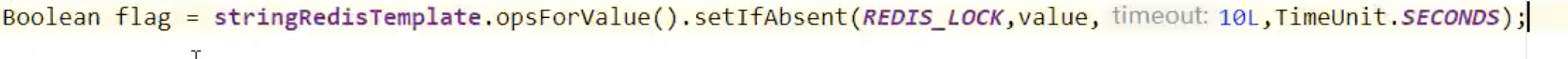
-
业务代码执行时间超过了过期时间,会造成问题,其他线程会进来或是误删其他线程的锁
通过在value中存储线程和流水号,来判断是否是自己的锁,如果是才能删

(这一步不是原子的操作(判断和删除没有原子性),存在问题,还是有可能误删) 解决:第一种:使用lua脚本(推荐 ) ;第二种:使用redis自身事务
官方lua:

完整示例:
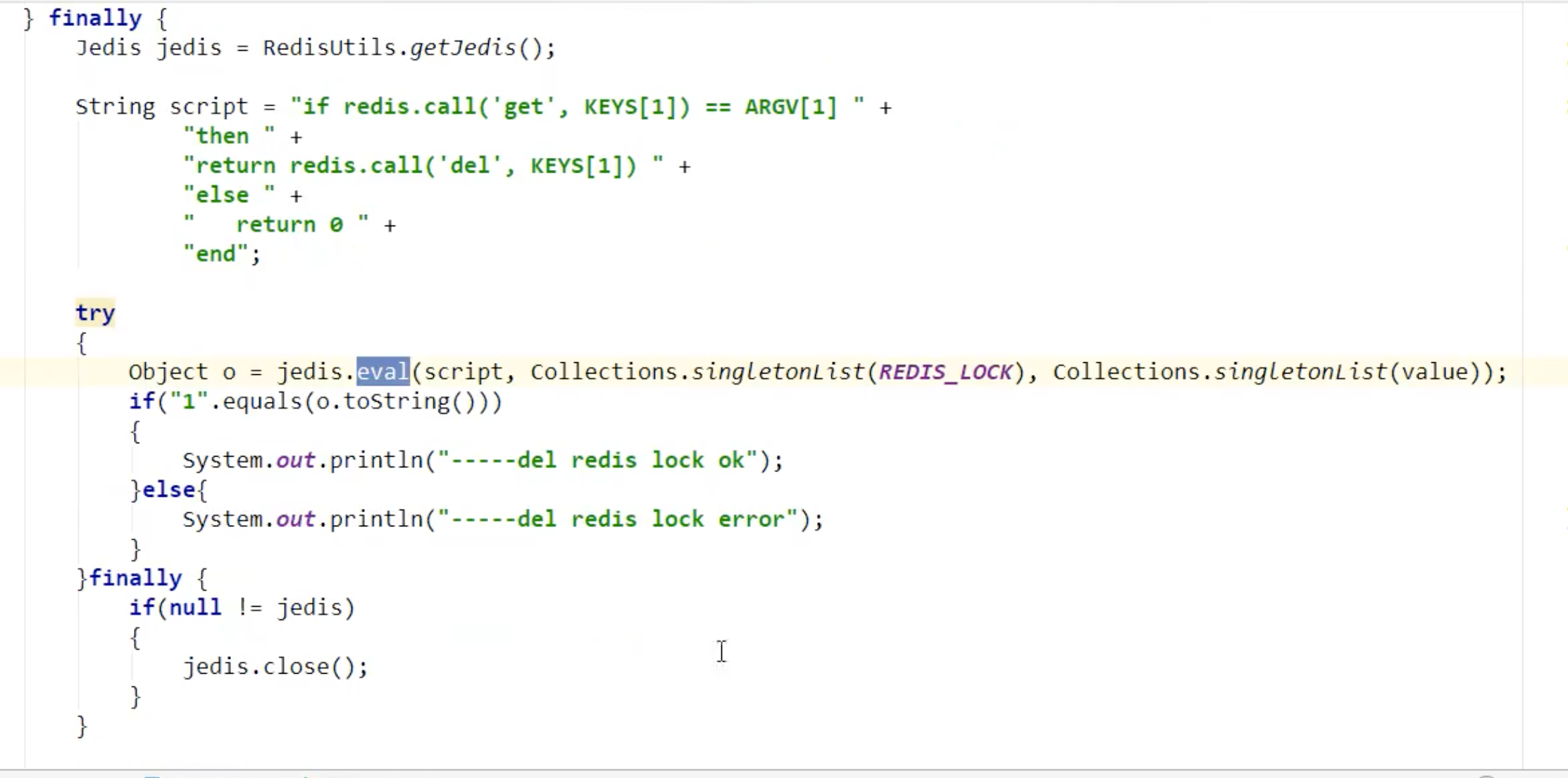
-
难点1:如何解决redis自动延时过期时间(防止业务代码执行超过了过期时间)
要到时间了进行检查,然后自动续期(缓存续命),难度太高,我们无法解决,使用Redisson
-
难点2:redis集群部署时分布式锁问题
AP:分区容错+高可用
主从模式可能遇到,在master加锁完成,但还没来得及同步到slave,造成主机上有,从机上没有,如果现在master降级。slave变master,那么此时没有锁信息,会造成其他的线程获得分布式锁成功。简称:redis异步复制造成锁丢失,比如:主节点没来得及把刚刚set进来的这条数据给从节点,就挂了。
使用zookeeper可以保持CP,数据一致性,不会出现这种问题,但是性能受限。因此如果真的出现redis这种问题了,再去修改数据排查
难度太高,我们无法解决,使用Redisson
-
Redisson 【最完善方案】
使用Redisson可以简化上面的大部分问题,甚至不需要写lua脚本
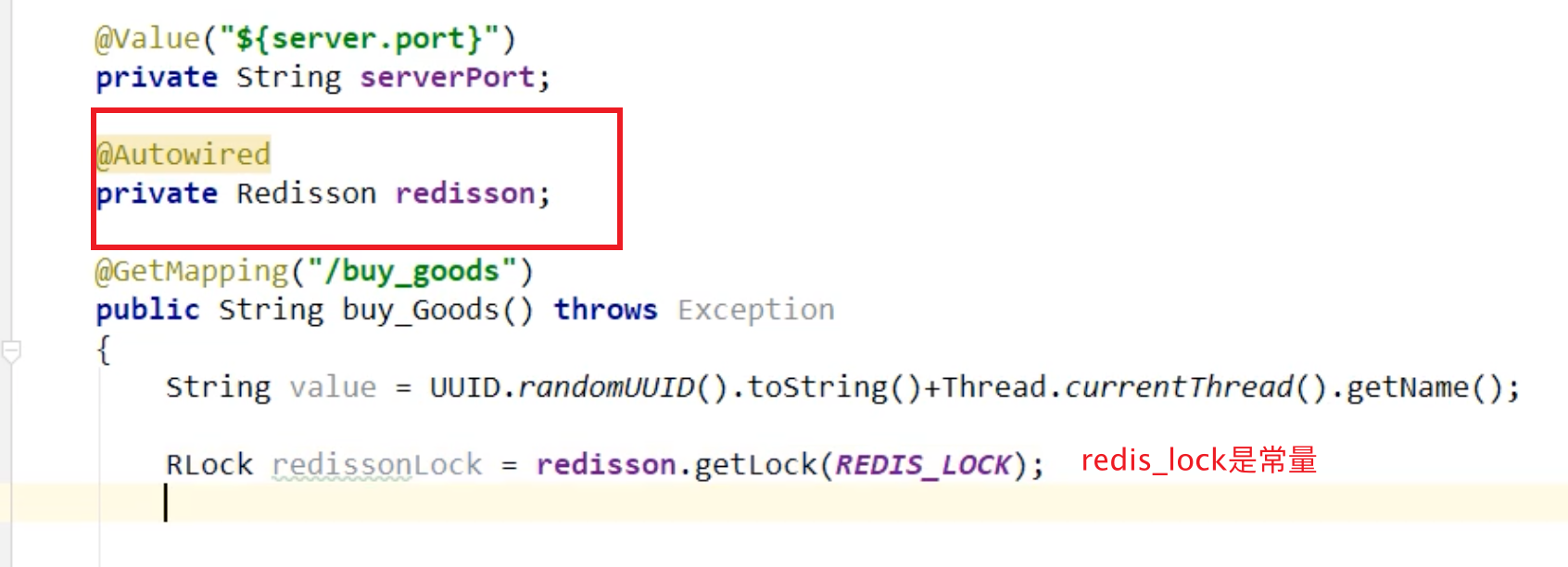

-
不需要考虑线程解锁是不是当前线程上的锁
-
不需要考虑自动延时过期时间问题
-
不需要考虑集群部署问题
-
有可能在高并发下会遇到某个异常:

即当前线程解的锁不是当前线程上的锁,解决:
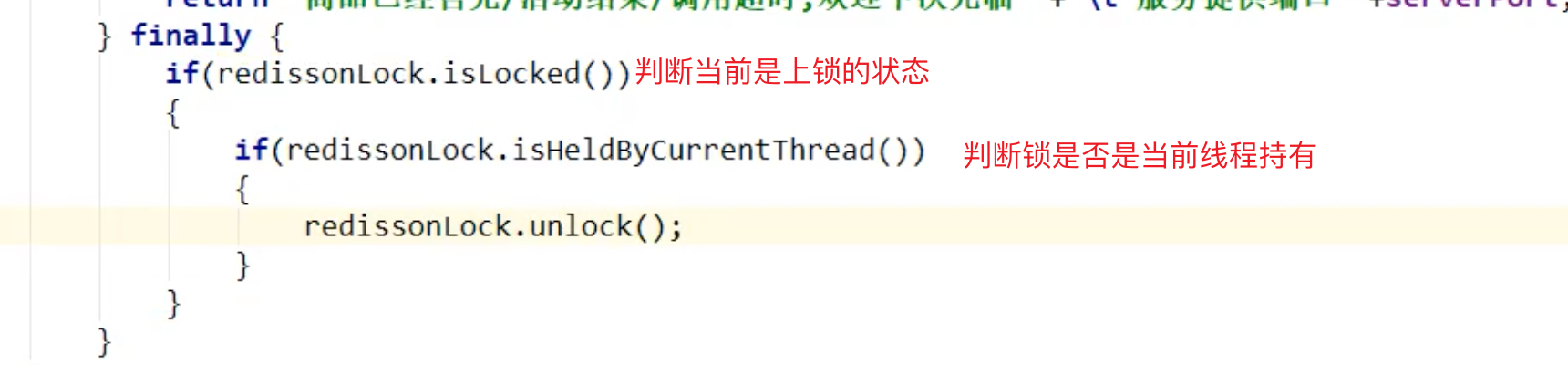
总结分布式锁需要考虑的问题:加锁原子性、解锁原子性、锁超时、死锁,误删别人的锁、自动续期、集群主机从机同步不及时导致失效
-
-
五、Jedis操作redis
我们需要使用java来操作redis
什么是Jedis:是Redis官方推荐的java连接开发工具! 使用ava操作Redis中间件! 如果你要使用java操作redis,那么一定要对Jedis十分的熟悉!
1.步骤
-
引入jar包,通过pom引入
<!-- 导入Jedis包 --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency> -
相关代码操作
// new Jedis 对象,设置连接信息 Jedis jedis = new Jedis("127.0.0.1", 6379); // 测试是否连接成功 String ping = jedis.ping(); System.out.println(ping); // 返回pong表示连接成功 // 执行指令 与redis命令相同,与spring的redisTemplate相比更加直观,且可以执行更多操作,如setnx,lset等 jedis.set("key1", "value1"); Long setnx = jedis.setnx("key1", "value1"); System.out.println(setnx); Long setnx2 = jedis.setnx("key2", "value1"); System.out.println(setnx2); // 判断key是否存在,删除 System.out.println(jedis.exists("key2")); jedis.del("key2"); System.out.println(jedis.exists("key2")); // list jedis.lpush("listKey", "value1"); jedis.lpush("listKey", "value2"); List<String> listKey = jedis.lrange("listKey", 0, -1); System.out.println(listKey); // set hash 等略 // 查看所有key Set<String> keys = jedis.keys("*"); System.out.println(keys); // 关闭 jedis.close();
2.Jedis事务
可以在java代码执行成功后才提交事务,这样就可以保证redis中的值在java代码执行成功后才会set进去,但是如果set指令时出现异常,对于执行成功的redis命令,不能回滚。
// new Jedis 对象,设置连接信息
Jedis jedis = new Jedis("127.0.0.1", 6379);
// 开启事务
Transaction multi = jedis.multi();
try {
multi.set("user1", "value1");
multi.set("user2", "value2");
int i = 1 / 0; // 这步java代码异常
multi.exec(); // 因为这里才提交redis事务,上一步抛了异常,所以无法执行到这里,未提交则上面的指令都不会执行
} catch (Exception e) {
multi.discard(); //放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
}
try {
multi.set("user1", "value1");
multi.set("user2", "value2");
multi.exec(); // 已经提交了事务,后面异常也不会回滚
int i = 1 / 0; // 这步java代码异常
} catch (Exception e) {
multi.discard(); //放弃事务
e.printStackTrace();
} finally {
System.out.println(jedis.get("user1"));
System.out.println(jedis.get("user2"));
jedis.del("user1");
jedis.del("user2");
jedis.close();
}
六、redis订阅发布
Redis发布定于(pub/sub)是一种消息通信模式:发送者pub发送消息,订阅者sub接收消息。类似微信、微博关注订阅机制 ,只要订阅了就可以收到信息。 【推荐使用消息队列会更简便一点】
Redis客户端可以订阅任意数量的频道。
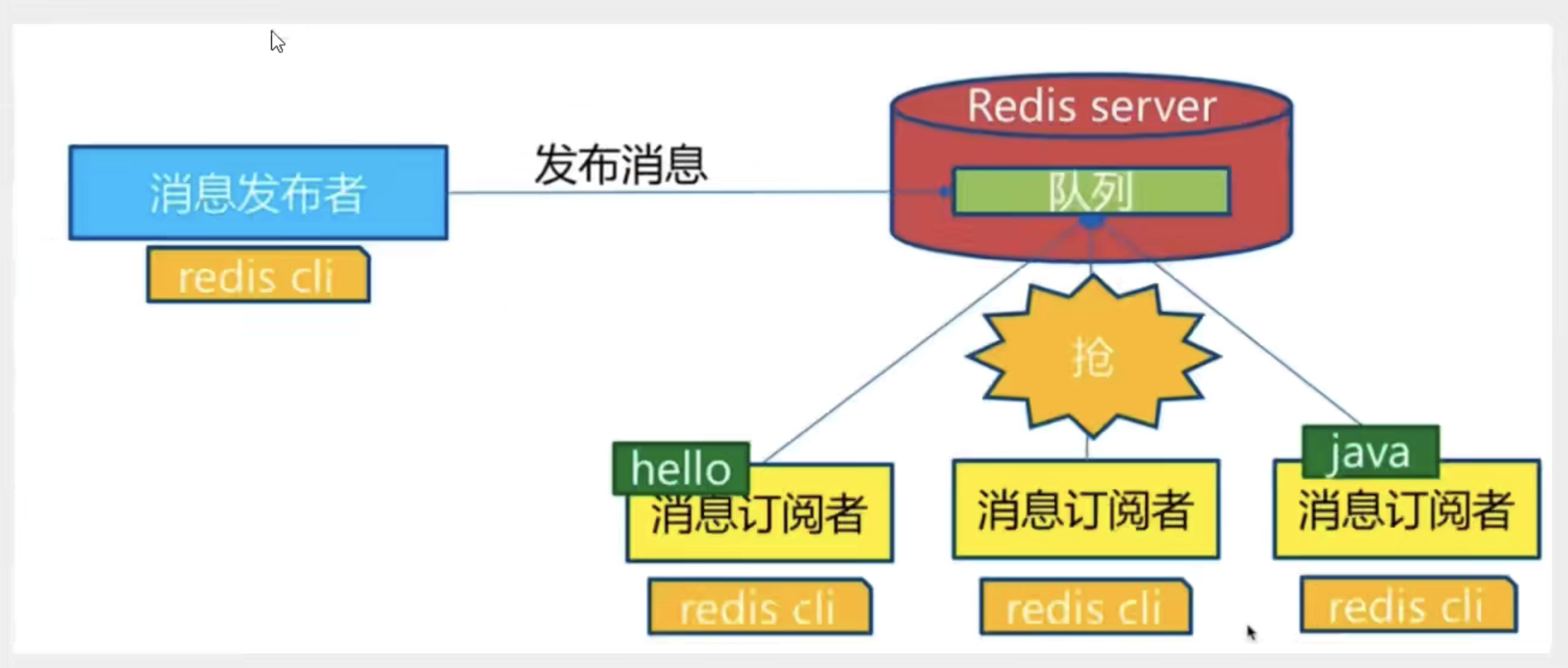
1.使用
订阅Subscribe:
# 订阅hhw频道,使用subscribe命令直接进入监听状态,hhw为频道名(不需要显示手动新建频道),当有新消息在该频道发布时,会直接追加显示最新的消息
local:0>subscribe hhw
Switch to Pub/Sub mode. Close console tab to stop listen for messages.
1) "subscribe"
2) "hhw"
3) "1"
1) "message"
2) "hhw"
3) "hello"
1) "message"
2) "hhw"
3) "helloredis"
发布Publish:
# 发布信息至hhw频道,使用publish命令,hhw为频道名,后面为发布的内容,返回1表示发布成功
local2:0>publish hhw hello
"1"
local2:0>publish hhw helloredis
"1"
2.使用场景
- 实时消息系统
- 实时聊天(频道当做聊天室,将信息回显给所有人即可)
- 订阅、关注系统
- 稍微复杂的场景建议使用消息中间件MQ
七、集群、主从复制
主从复制、读写分离
1.概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);
- 数据的复制是单向的,只能由主节点到从节点。Masterl写为主,Slave 以读为主。
- 默认情况下 ,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
- 主从复制的作用主要包括: 1、数据冗余:主从复制实现了数据的热备份 ,是持久化之外的一种数据冗余方式。 2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的元余。 3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载:尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。 4、高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础 ,因此说主从复制是Redis高可用的基础。
- 一般来说,要将Redis运用于工程项目中,只使用一台Redis是万万不能的,原因如下: 1、从结构上 ,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大; 2、从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存诸內存 单台redis最大使用内存不应该超过20G
- 通常使用一主二从
2.配置(1主2从)
只需要配置从库,因为redis默认就是主库
local:0>info replication # 查看当前库的信息
"# Replication
role:master # 角色:默认主库
connected_slaves:0 # 从机数量
master_replid:493a3a65df6d0be05c38bc66377dbc136cfbe8f1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
"
1.复制redis配置文件,修改配置文件(端口、pid、log文件名、dumo.rdb文件名)启动,即可实现单机多集群
# MAC 根据配置文件启动命令:
> redis-server /Users/hhw/redis-6380/redis.conf
> redis-server /Users/hhw/redis-6381/redis.conf
2.查看进程信息,可以看到开启了3个redis服务,集群服务搭建完成:
hhw@hhw ~ % ps -ef|grep redis
501 22157 1 0 六10上午 ?? 0:52.90 redis-server *:6379
501 14107 12633 0 9:12下午 ttys000 0:00.20 redis-server 127.0.0.1:6380
501 15799 15622 0 9:14下午 ttys001 0:00.15 redis-server 127.0.0.1:6381
501 20741 20615 0 9:20下午 ttys003 0:00.00 grep redis
3.搭建一主二从环境
一般情况下,只需要配置从机即可,因为每台redis默认是主机,这里把6379当主机,6380、6381当从机
以其中一台为例子,配置从机:
local6380:0>slaveof 127.0.0.1 6379 # 配置该从机的主机地址 (也可以通过配置文件去配置)
"OK"
local6380:0>info replication # 查看当前库的信息
"# Replication
role:slave # 角色:从机
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_repl_offset:14
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:2d58d4c7af94f3de3b517de91555c897bd4b7675
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:14
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:14
"
6381配置同理,此时6379为主机,有2台从机:6380、6381
local6379-2:0>info replication
"# Replication
role:master
connected_slaves:2 # 从机数量:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=238,lag=1 # 从机1 信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=238,lag=1 # 从机2 信息
master_replid:2d58d4c7af94f3de3b517de91555c897bd4b7675
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:252
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:252
"
4.主机可以读写,从机只读
往主机写入信息,实时同步到从机。从机不可写,会报错:"READONLY You can't write against a read only replica."
-
主机断开连接,从机依然是连接到主机的,但是没有写操作,这个时候,如果主机回来了,从机依然可以直接实时同步主机信息
-
如果是用命令行配置的,重启了从机会默认变为主机,断开期间的数据不会同步。但是如果设置成从机,数据立刻会同步过来,为什么呢?
复制原理:
- slave启动成功连接到master后会发送一个sync同步命令
- Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进利程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
- 全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:master继续将新的所有收集到的修改命令依次传给slave,完成同步
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
-
如果采用单链路的情况(79–80–81)此时80节点依然是从机,只读
3.宕机后手动配置主机
在哨兵模式出来之前,如果主机断开了连接,我们可以使用 slaveof no one命令手动配置该从节点为主机,然后再讲其他从几点手动切换到新的主机。
如果此时主节点恢复了,并不会自动切回来。
4.哨兵模式
(自动选举主节点模式)
概述
-
主从切换技术的方法是:当主服务器宕机后,需需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。Redis从2.8开始正式提供了Sentinel(哨兵) 架构来解决这个问题。
-
谋朝篡位的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
-
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
-
查看redis目录下,可以看到哨兵文件
runtest-sentinel
hhw@hhw redis-5.0.8 % ls 00-RELEASENOTES bin runtest-moduleapi BUGS db runtest-sentinel CONTRIBUTING deps sentinel.conf COPYING dump.rdb src INSTALL etc tests MANIFESTO redis.conf utils Makefile runtest README.md runtest-cluster
结构
-
哨兵作用
- 通过发送命令,让Redis服务器返回监控运行状态,包含主服务器和从服务器
- 当哨兵检测到master宕机,会自动将slave切换到master,然后通过发布订阅模式通知其他从服务器,让他们切换主机
-
单哨兵也有可能出现问题,所以需要使用多少兵进行监控,哨兵之间也会互相监控,形成多哨兵模式
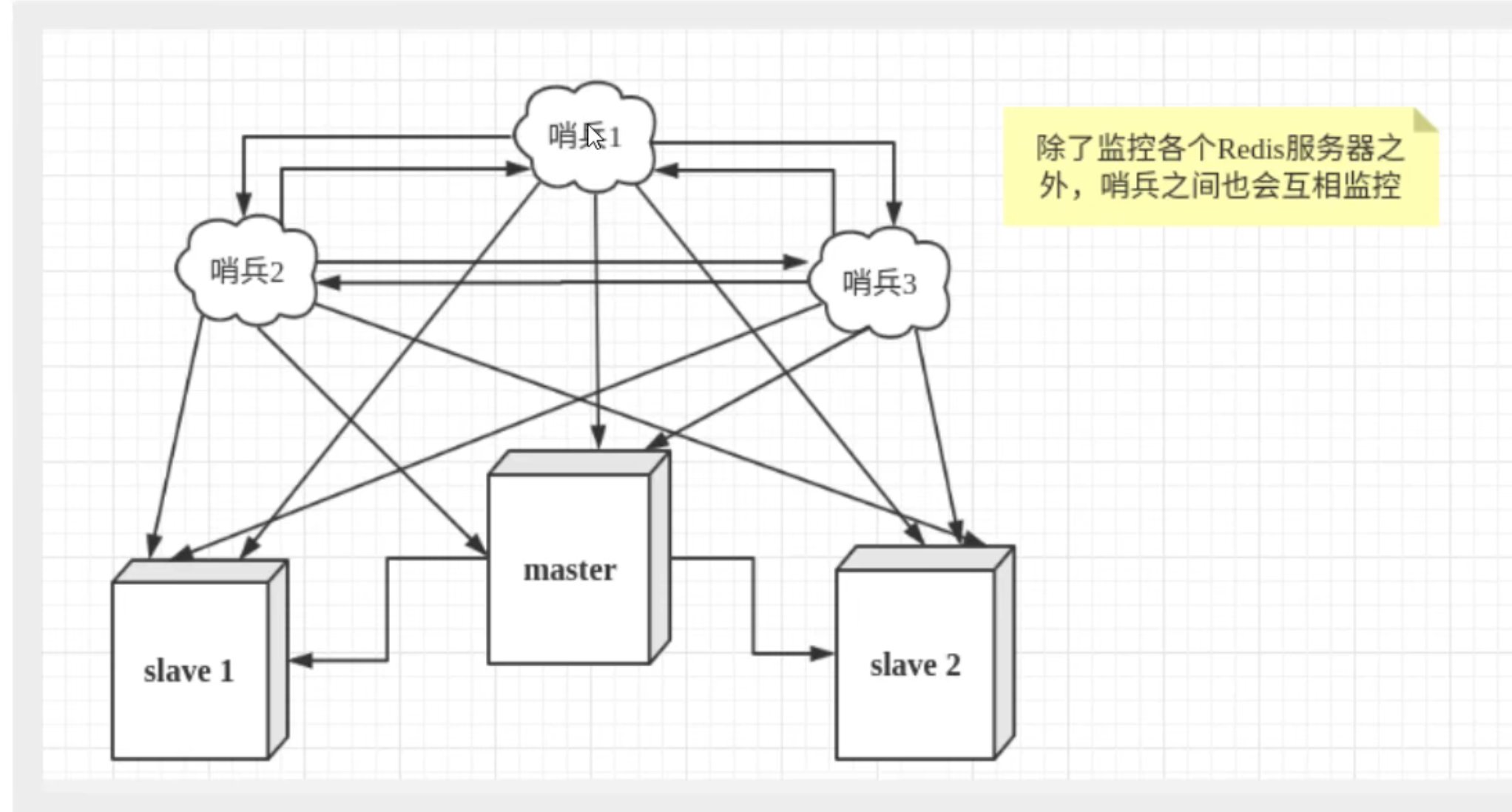
假设主服务器宕机,哨兵1先检测到这个结果 ,系统并不会马上进行failover过程 ,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover故障转移]操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。
配置(单)哨兵模式
-
配置哨兵配置文件 sentinel.conf
配置以下内容
sentinel monitor myredis 127.0.0.1 6379 1 # 后面这个数字 1 ,代表主机挂了,slave投票选取新的主机,票数多的当选 -
启动哨兵
hhw@hhw redis-5.0.8 % redis-sentinel /usr/local/redis-5.0.8/sentinel.conf 67999:X 07 Dec 2021 21:15:41.288 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 67999:X 07 Dec 2021 21:15:41.288 # Redis version=5.0.8, bits=64, commit=00000000, modified=0, pid=67999, just started 67999:X 07 Dec 2021 21:15:41.288 # Configuration loaded 67999:X 07 Dec 2021 21:15:41.289 * Increased maximum number of open files to 10032 (it was originally set to 2560). _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 5.0.8 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in sentinel mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 26379 | `-._ `._ / _.-' | PID: 67999 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 67999:X 07 Dec 2021 21:15:41.300 # Sentinel ID is 212241566fc6148d471fa6cb6f321c0f923964fd 67999:X 07 Dec 2021 21:15:41.300 # +monitor master mymaster 127.0.0.1 6379 quorum 1 67999:X 07 Dec 2021 21:15:41.301 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # 从机 6381 67999:X 07 Dec 2021 21:15:41.301 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 # 从机 6380
实际测试
-
如果master节点断开了,此时会选取新的主机(投票算法略)
哨兵会出现以下日志:
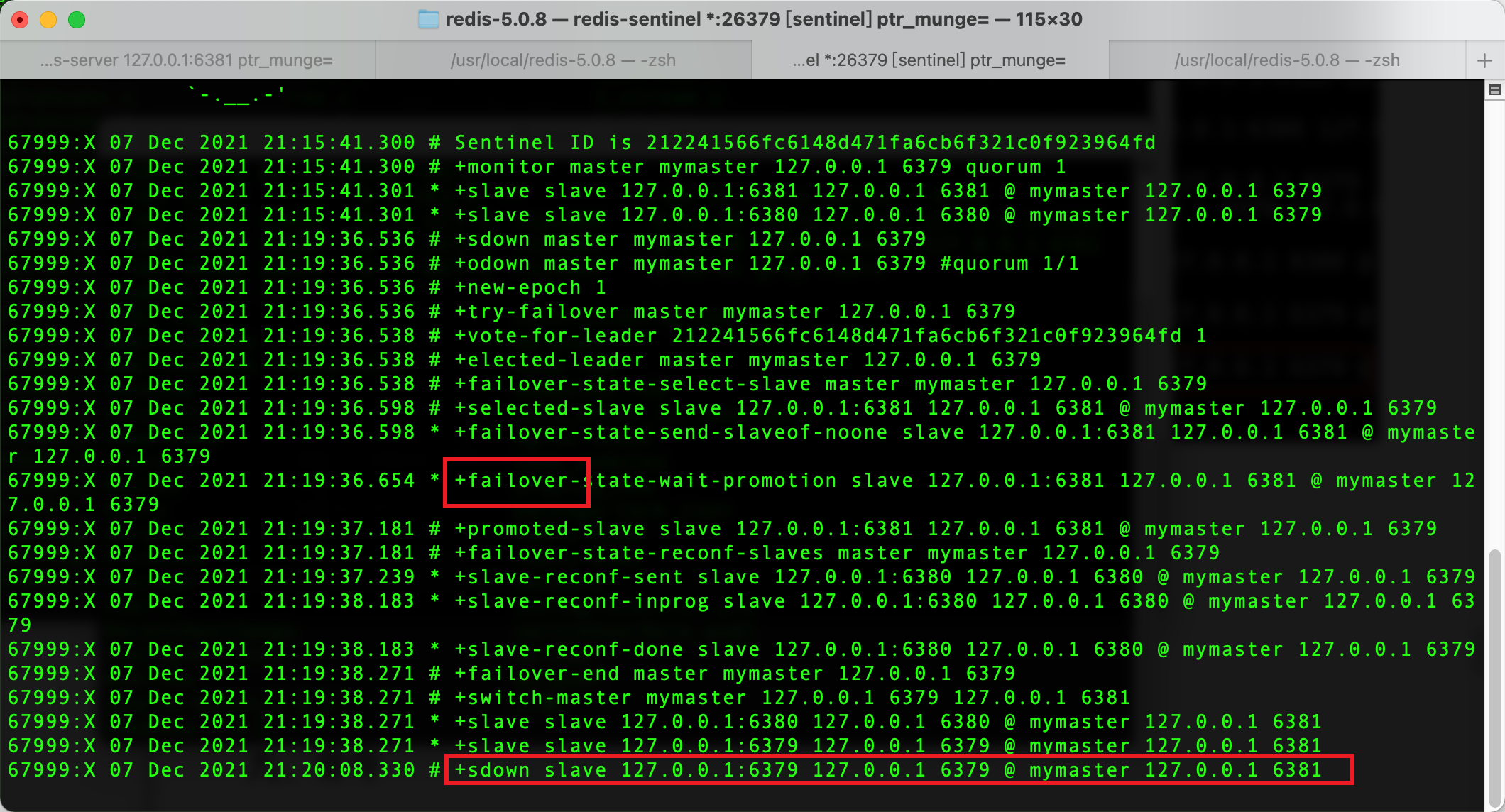
-
如果master重新连接,那么原master会变成从机slave,这就是哨兵模式的规则
* +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381
小计
- 哨兵集群,基于主从复制,所有的主从配置优点,都有
- 主从可以切换,故障可以转移,系统可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动,更加健壮
- 缺点:Redis不好在线扩容;实现哨兵模式的配置比较麻烦(选项较多)一般由运维来配置
八、缓存过期淘汰策略
九、命令
-
常用命令
-
查看版本
redis-server -v # 或 进到redis中,输入info命令 -
查询、清空
keys * #查看所有key flushdb #清空当前库 flushall #清空全部数据库 exists [key] #查询某个key是否存在 expire [key] [秒] #设置某个key几秒后过期 ttl [key] #查看当前key的剩余时间 type [key] #查看key的类型 -
同时设置/获取多个键值对(string类型)
mset k1 v1 k2 v2 k3 v3 //设置 mget k1 v1 k2 v2 k3 v3 //获取 -
数值增减
// 增加数字 INCR key // 增加指定整数 INCRBY key increment // 递减数字 DESC key // 减少指定整数 DECRBY key decrement例如增加数字,只需要设置key,之后key对应的value会自增(场景:点赞数;阅读数;商品编号、订单号生成)
-
获取字符串长度
STRLEN key -
分布式锁
// 第一种:不存在创建;存在创建失败 setnx key value // 第二种 // EX: key在多少秒之后过期 PX:key在多少毫秒之后过期 // NX:当key不存在的时候,才创建key,效果等同setnx // XX:当key存在的时候,覆盖key set key value [EX seconds] [PX milliseconds] [NX|XX] 示例:set lock value ex 10 nx -
list
> LPUSH list one #将一个值或多个值插入到列表的头部(左侧),RPUSH插入到(尾部)右侧 > LPUSH list two > LPUSH list three # 则现在list中有3个值, > LRANGE list 0 -1 # 从左往右遍历 -1表示全部 three two one > LPOP #移除(左侧第一个元素) RPOP 移除右侧第一个元素 > lindex list 0 #通过下标获取值 three # 移除list中指定个数的value,精确匹配 > lrem list 1 one #精确移除,移除list中的one,且移除1个就可以了(list中可以有重复的值) > lrem list 2 one #精确移除,移除list中的one,且移除2个(list中可以有重复的值) # 只保留指定下标的元素 > ltrim list 1 2 #只保留index为1和2的元素 -
set
> SDIFF key1 key2 #取key1和key2的差集(以key1为基准,key1 a b c,key2 b c d,则差集为a) > SINTER key1 key2 #取交集(以上面为例,交集:b,c) > SUNION key1 key2 #取并集
-
-
Redis命令不区分大小写,但是Redis的key区分大小写
十、redis的乐观锁
使用场景:在redis事务中可开启,同时有事务A、B影响同一个key (以A1为例),如果事务A对A1减去20但未提交,事务B对A1加上20完成并提交了,此时事物A再去提交事务回提示失败!
相当于mysql的version
使用watch命令开启:
127.0.0.1:6379> set money 100 OK
127.0.0.1:6379>set out 0 OK
127.0.01:6379> watch money #监视 money对象
OK
127.0.01:6379>multi #事务正常结束,数据期间没有发生变动,这个时候就正常执行成功!
OK
127.0.0.1:6379> DECRBY money 20 QUEUED
127.0.01:6379>INCRBY out 20 QUEUED
127.0.0.1:6379>exec # 执行完会自动解锁,无需手动输入unwatch
1)(integer)80
2)(integer)20
案例:
127.0.0.1:6379> watch money #监视 money
OK I
127.0.0.1:6379>multi OK
127.0.0.1:6379>DECRBY money 10 QUEUED
127.0.01:6379>INCRBY out 10 QUEUED
127.0.0.1:6379>exec #执行之前,另外一个线程,修改了我们的值,这个时候,就会导致事务执行失败!(ni1)
十一、Redis序列化
在使用redisTemplate时,需要使用自定义redisTemplate的方式去指定序列化方式,否则存中文可能会被转移,默认的序列化方式是采用JDK序列化的方式,我们最好使用json的方式。
-
redis在存储对象的时候,需要序列化(实现Serializable接口),否则会报错
-
改变redis的序列化方式,使对象内容正常显示:
通过写redis配置类的方式
十二、Redis持久化
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以Redis提供了持久化功能!
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
RDB(Redis DataBase)
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中主进程是不进行任何IO操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感那RDB方式要比AOF方式更加的高效。RDB的缺点:最后一次持久化后的数据可能丢失。我们默认的就是RDB,一般情况下不需要修改这个配置!
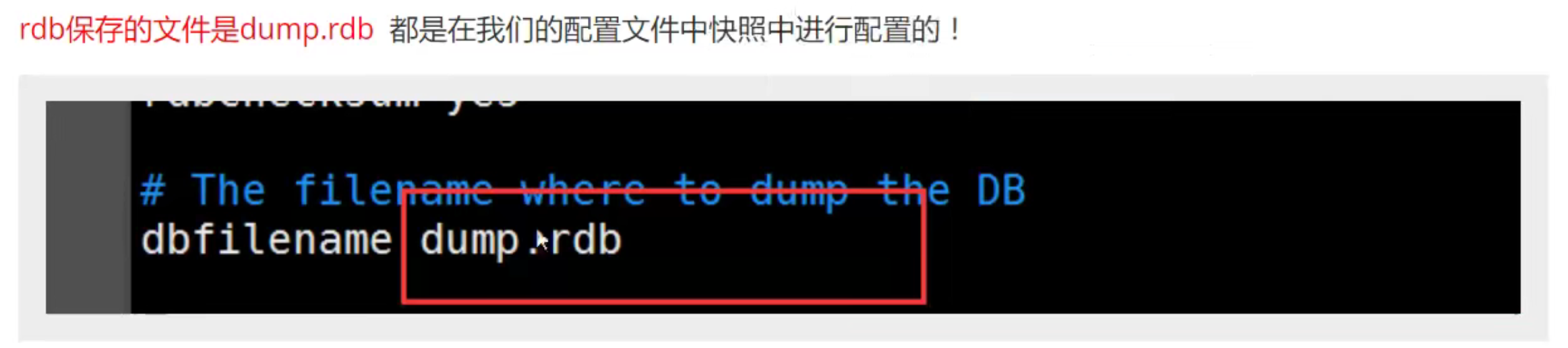
触发rdb保存条件:
- 执行了 flushall命令
- 满足save规则
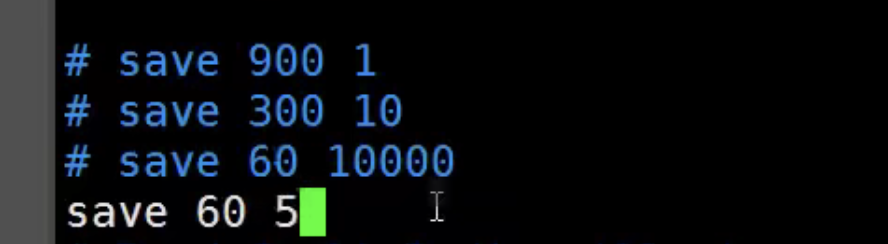
save 900 1 #900秒内,如果至少有1个操作就会触发持久化
save 60 5 #60秒内,如果至少有5个操作就会触发持久化
- redis正常关机
如何恢复rdb文件:
- 把rdb文件放在redis启动目录下,redis启动时会自动检查dump.rdb文件,恢复其中的数据
总结:几乎使用redis的默认rdb配置就够用了
- 优点:适合大规模数据恢复
- 缺点:对数据完整性要求不高,需要一定的时间间隔才回进行一次rdb,如果redis宕机,那么最后一次还没保存的数据就丢失了
- 在主从复制中,rdb就是备用,放在从机上面
AOF(Append Only File)
将所有命令都记录下来,history,恢复的时候就把所有的记录都执行一边,类似日志。
以日志的形式来记录每个写操作,将Redis执行过过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件redis启动之初会读取该文件重新构建数据,换言之, redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。 Aof保存的是appendonly.aof文件,默认不开启这个配置,需要手动在配置文件中配置
触发条件
- 由配置文件中而定,一般设置成一秒钟同步一次,一般只会丢失1秒钟的数据
如何恢复aof文件:
- aof是可以认为篡改的,如果aof文件有误,可以使用redis-check-aof –fix 命令修复aof文件
- 如果文件正常,重启redis就可以直接恢复
总结
-
优点:每次修改都会同步,文件完整性好
-
缺点:相对于数据文件来说,aof大小远远大于rdb,恢复速度比rdb慢
aof运行效率低,所以redis默认rdb