一、安装es
略
查询节点信息192.168.100.24:9200/_nodes
查询版本信息http://192.168.4.77:9200/
1.1启动&关闭ES
# 启动
systemctl start elasticsearch
# 关闭
systemctl stop elasticsearch
1.2日志
cd /var/log/elasticsearch
tail -200f elasticsearch.log
二、安装kibana
略
http://192.168.100.24:5601/
2.1启动kibana
nohup ./kibana --allow-root &
三、拼音分词器
3.1安装
3.1.1参考
https://blog.51cto.com/u_15034497/2614884
https://github.com/medcl/elasticsearch-analysis-pinyin
(拼音分词器要下载同版本的,不然会启动不了)
3.1.2创建索引(setting)
-
安装完成后,重启es。P.S. 若启动失败查看日志的路径
/var/log/elasticsearch -
创建pinyin索引 ,这里以pinyindata为例
PUT http://192.168.100.24:9200/{index索引名称}/
{
"settings" : {
"analysis" : {
"analyzer" : {
"pinyin_analyzer" : {
"tokenizer" : "my_pinyin"
}
},
"tokenizer" : {
"my_pinyin" : {
"type" : "pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
}
}
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "medcl"
}
- 判断拼音分词器是否创建成功
POST http://192.168.100.24:9200/pinyindata/_analyze
{
"text":["小吴"],
"analyzer":"pinyin_analyzer"
}
{
"tokens": [
{
"token": "xiao",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "小吴",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "xw",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "wu",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
}
]
}
3.1.3创建mapping(相当于建表结构)
- 发送请求
POST http://192.168.100.24:9200/pinyindata/_mapping
{
"properties": {
// 创建name字段 type=keyword
"name": {
"type": "keyword",
"fields": {
"pinyin": {
"type": "text",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
}
}
}
{
"acknowledged": true
}
3.1.4插入数据
- 执行请求,或使用api插入
http://192.168.100.24:9200/pinyindata/_create/{id}
{
"name": "王德发"
}
3.1.5拼音搜索
- 通过API执行搜索
http://192.168.100.24:9200/pinyindata/_search?q=name.pinyin:wdf
- 代码执行
<dependency>
<groupId>cn.easy-es</groupId>
<artifactId>easy-es-boot-starter</artifactId>
<version>1.0.2</version>
</dependency>
代码示例RestHighLevelClient:
// 标准es查询语法,拼音模糊搜索
//创建复杂查询对象---------
SearchRequest searchRequest = new SearchRequest("pinyindata");
//创建一个条件对象用来封装各种条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//创建一个对象来封装查询条件query
MatchQueryBuilder queryBuilder = new MatchQueryBuilder("name.pinyin","xw");
//使用条件对象来封装查询条件---条件
sourceBuilder.query(queryBuilder);
//指定查询的列------条件
String[] arr = {"id", "name"};
String[] att = {};
sourceBuilder.fetchSource(arr,att); //指定查询列和不查询列
//分页查询---条件
sourceBuilder.from(0);
sourceBuilder.size(5);
//排序----条件
// SortOrder sortOrder = SortOrder.ASC;------定义排序方式
sourceBuilder.sort("name", SortOrder.DESC);
//创建一个高亮对象,封装高亮条件
HighlightBuilder highlightBuilder = new HighlightBuilder();
//指定高亮列----也可以用fields,全局定义高亮
highlightBuilder.field("name");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
sourceBuilder.highlighter(highlightBuilder);
//将封装好的条件对象给searchRequest
searchRequest.source(sourceBuilder);
//将封装好所有条件的对象给查询方法
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
//输出根据条件查出的总条数
System.out.println("命中条数/查询总数:"+search.getHits().getTotalHits().value);
//将查出的数据封住为一个数组
SearchHit[] hits = search.getHits().getHits();
//遍历数组
Arrays.stream(hits).forEach(item->{
//输出遍历对象
System.out.println(item.getSourceAsString());
});
Arrays.stream(hits).forEach(item->{
//遍历输出高亮的字段
System.out.println(item.getHighlightFields());
});
四、ES基本概念
es的核心概念主要是:index(索引)、Document(文档)、Clusters(集群)、Node(节点)与实例,下面我们先来了解一下Document与Index。
4.1文档
es是面向文档的,文档是es中可搜索的最小单位,es的文档由一个或多个字段组成,类似于关系型数据库中的一行记录,但es的文档是以JSON进行序列化并保存的,每个JSON对象由一个或多个字段组成,字段类型可以是布尔,数值,字符串、二进制、日期等数据类型。
es每个文档都有唯一的id,这个id可以由我们自己指定,也可以由es自动生成。
{
"_index" : "test_logs2",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"uid" : 1,
"username" : "test"
}
}
以上内容构成:
-
_index:文档所在的索引名称
-
_source:原始json数据(真正存储内容的地方)
-
_type:文档所属类型,es7.0以后只有为 doc
-
_version:文档版本,用来记录修改次数,递增
-
_id:文档的id,如果不指定的话,ES会自动赋值
注意:指定index进行insert文档时,如果index已存在,不会像数据库一样报错,而是会进行覆盖,并且文档的字段 _version会加1
4.2索引
es索引,是es组织文档的方式,一个索引下包含多个文档,可以把es的索引类比为关系型数据库的一张数据表。创建索引时,通常需要配置以下属性:setting、mapping、alias(略)。
4.2.1Mapping
- mapping是用来定义文档对象的属性,可以类比到表的列字段。
POST http://192.168.100.24:9200/pinyindata/_mapping
{
"properties": {
// 创建name字段 type=keyword
"name": {
"type": "keyword",
"fields": {
"pinyin": {
"type": "text",
"store": false,
"term_vector": "with_offsets",
"analyzer": "pinyin_analyzer",
"boost": 10
}
}
}
}
}
4.2.2Setting
-
setting主要用来限定索引的一些行为。例如节点分配、分区个数(将索引的数据分成多少份存储)、副本个数、分词器引擎
-
参考三、拼音分词器
五、RestHighLevelClient
5.1集成到SpringBoot
5.1.1引入pom
注意spring版本、es客户端版本要和es的相对应,这里所使用的ES版本为:7.17.6,SpringBoot使用2.7.x
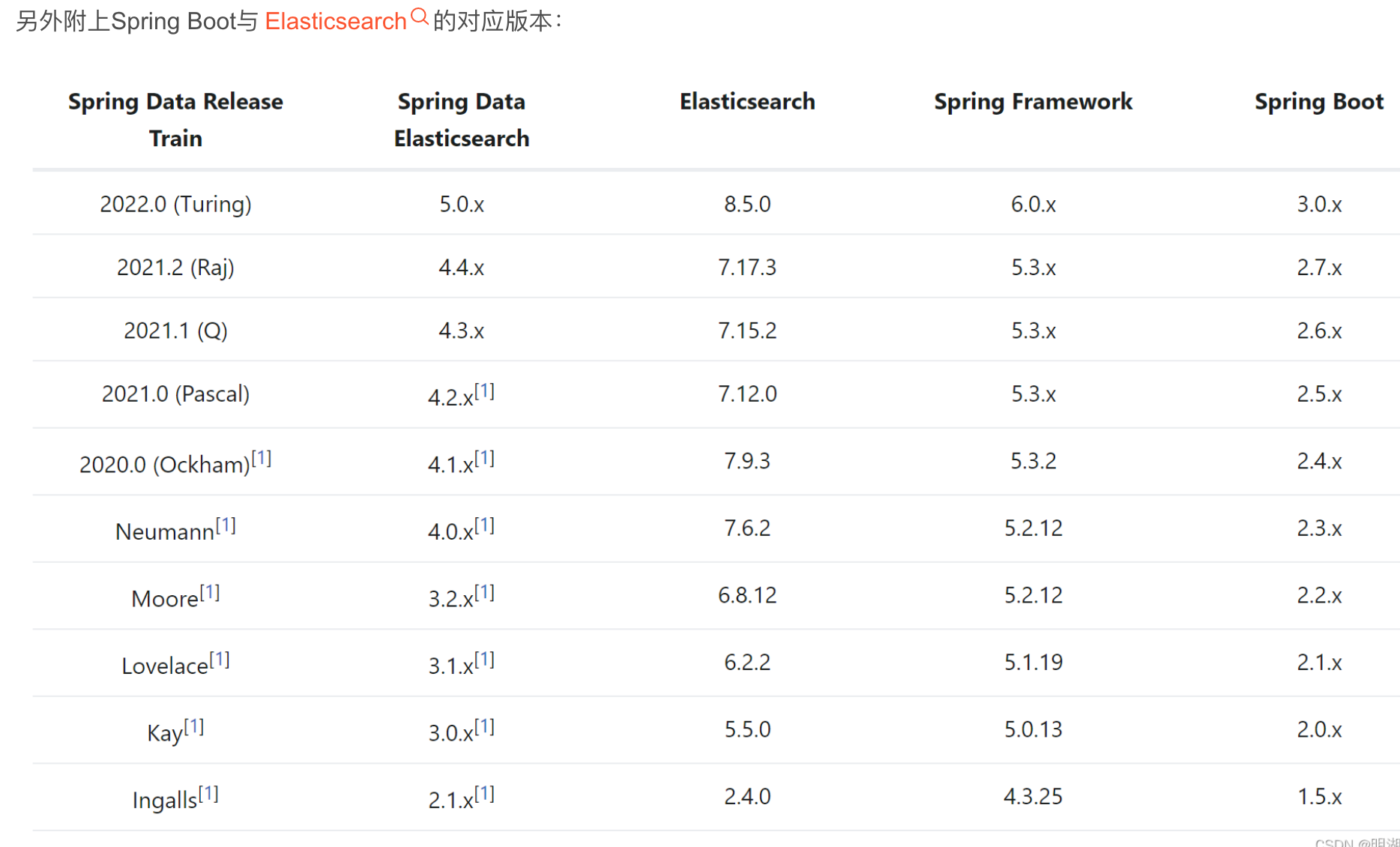
<!-- es client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<!--<version>7.17.6</version>-->
</dependency>
<!-- elasticsearch-rest-high-level-client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<!--<version>7.17.6</version>-->
</dependency>
- 去掉版本号,由SpringBoot来管理,避免出现不兼容的情况
5.1.2让Spring进行管理@Bean
@Configuration
public class EsConfig {
@Value("${es.host}")
private String esHost;
@Value("${es.port}")
private Integer esPort;
@Bean
public RestHighLevelClient getRestHighLevelClient(){
HttpHost http1 = new HttpHost(esHost, esPort, "http");
// 节点2: HttpHost http2 = new HttpHost("127.0.0.1", 9201, "http");
RestClientBuilder restClientBuilder = RestClient.builder(http1);
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(restClientBuilder);
return restHighLevelClient;
}
}
5.1.3尝试注入一个client
- 交给Spring管理后,就可以直接注入使用了!
@Autowired
private RestHighLevelClient restHighLevelClient;
5.2使用client对ES进行操作
5.2.1创建索引
略
5.2.2新增文档与批量导入
5.2.2.1 单条插入
Map<String, Object> map = new HashMap<String, Object>() ;
IndexRequest indexRequest = new IndexRequest("pinyindata").type("_doc").id(String.valueOf(map.get("id"))).source(map);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
5.2.2.1 批量插入
- 从关系型表中查询数据并插入到ES
//t_project为表名
List<Entity> projectList = Db.use().findAll("t_project");
List<Map<String, Object>> addList = new ArrayList<>();
for (Entity entity : projectList) {
Long id = entity.getLong("id");
String projectName = entity.getStr("project_name");
Map<String, Object> map = new HashMap<String, Object>() ;
addList.add(map);
}
BulkRequest bulkRequest = new BulkRequest();
addList.forEach(s -> bulkRequest.add(new IndexRequest().index("pinyindata").type("_doc").id(s.get("id").toString()).source(s)));
bulkRequest.timeout(TimeValue.timeValueSeconds(5));
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
5.2.3修改文档
@GetMapping("/update")
public void update() throws IOException {
// 指定id更新
UpdateRequest updateRequest = new UpdateRequest("pinyindata", "_doc", "5155195438038622213")
.doc(new HashMap<String, Object>() );
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
}
- 修改后查询
// 根据id获取文档
@GetMapping("/getDocByID")
public Map<String, Object> getDocByID(String id) {
Map<String, Object> map = new HashMap<>();
SearchRequest searchRequest = new SearchRequest("pinyindata");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.termQuery("_id", id));
searchRequest.source(searchSourceBuilder);
try {
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (searchResponse.status() == RestStatus.OK) {
map = searchResponse.getHits().getAt(0).getSourceAsMap();
}
} catch (Exception e) {
e.printStackTrace();
}
return map;
}
{
"name": "h宾馆",
"id": 5155195438038622213
}
5.2.4删除文档
- 根据id删除
@GetMapping("/delete")
public void deleteById(String id) throws IOException {
DeleteRequest deleteByQueryRequest = new DeleteRequest("pinyindata", "_doc", id);
restHighLevelClient.delete(deleteByQueryRequest, RequestOptions.DEFAULT);
}
5.2.5列表查询
5.2.5.1不分页
//1.创建 SearchRequest搜索请求 指定要查询的索引
SearchRequest searchRequest = new SearchRequest("pinyindata");
//2.创建 SearchSourceBuilder条件构造。builder模式这里就先不简写了
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
/*// 2.1创建一个对象来封装查询条件query,使用拼音分词器->字段名.pinyin进行拼音搜索
MatchQueryBuilder queryBuilder = new MatchQueryBuilder("name.pinyin","xw");*/
// 2.2查询全部
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
searchSourceBuilder.query(queryBuilder);
//3.将 SearchSourceBuilder 添加到 SearchRequest中
searchRequest.source(searchSourceBuilder);
//4.执行查询
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//5.解析查询结果
System.out.println(searchResponse);
System.out.println("花费的时长:" + searchResponse.getTook());
SearchHits hits = searchResponse.getHits();
System.out.println(hits.getTotalHits());
System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
5.2.5.1分页
ArrayList<Map<String, Object>> resultList = new ArrayList<>();
SearchRequest searchRequest = new SearchRequest("pinyindata");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
/*分页参数 es默认最大查询数量10000*/
.from(0).size(10000)
/*查询条件*/
.query(QueryBuilders.matchQuery("name.pinyin", projectName));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (searchResponse.status() == RestStatus.OK) {
SearchHits searchHits = searchResponse.getHits();
for (SearchHit searchHit: searchHits) {
resultList.add(searchHit.getSourceAsMap());
System.out.println(searchHit.getSourceAsMap());
}
}
return resultList;
5.2.5复杂的列表查询
略,见:https://blog.csdn.net/qq_42402854/article/details/126615064
资料参考:https://www.jianshu.com/p/d1c83284dcb3
六、MySQL与ES数据同步方案
整合此篇文章:https://blog.csdn.net/w1014074794/article/details/127124574